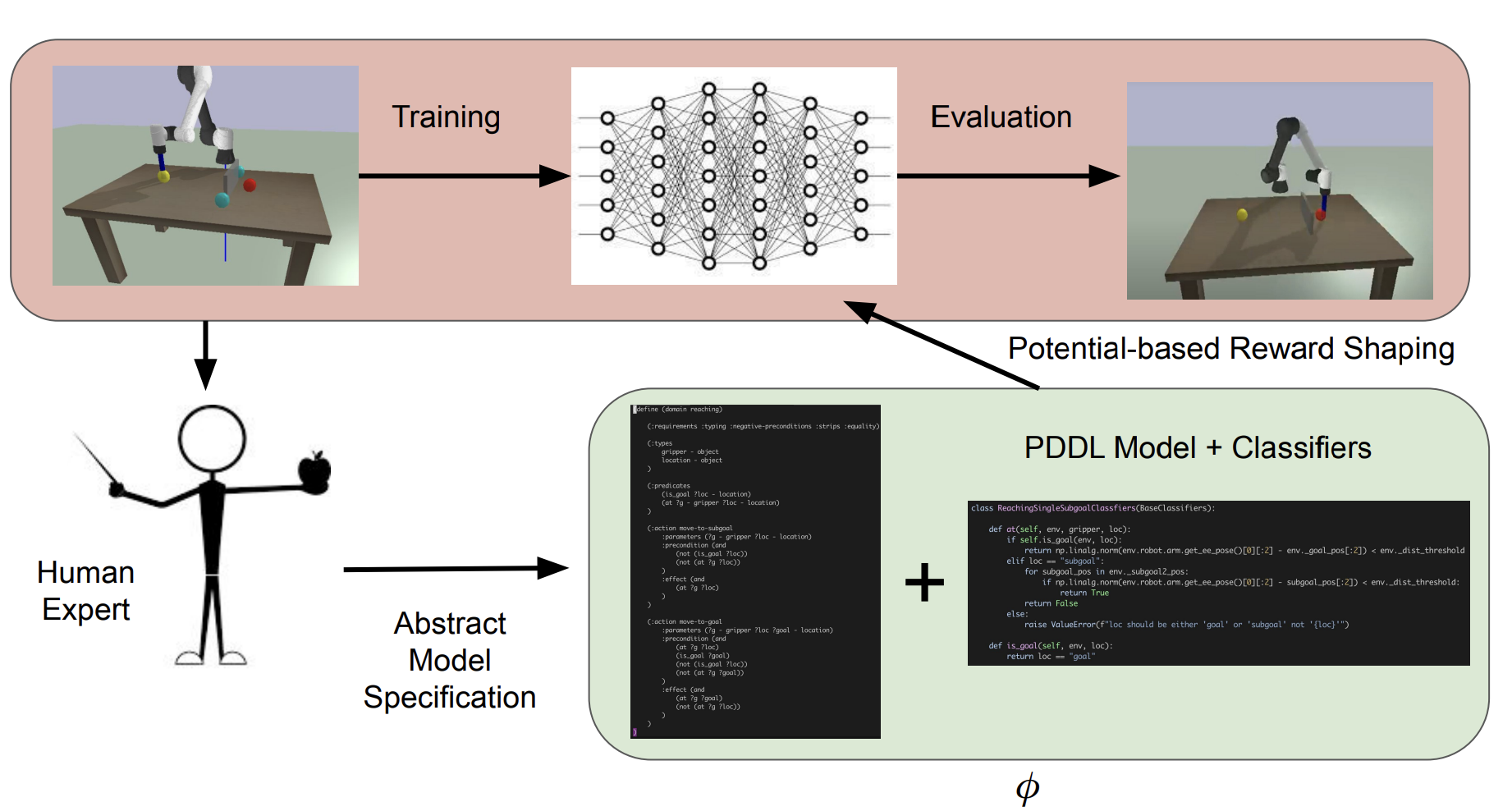
Automatic Reward Densification
Classical planning over human-specified PDDL models, combined with potential-based shaping, densifies sparse rewards and speeds up learning across robotic tasks.

Classical planning over human-specified PDDL models, combined with potential-based shaping, densifies sparse rewards and speeds up learning across robotic tasks.

Prototype wearable combines OCR and face recognition to support blind users with reading and social identification.
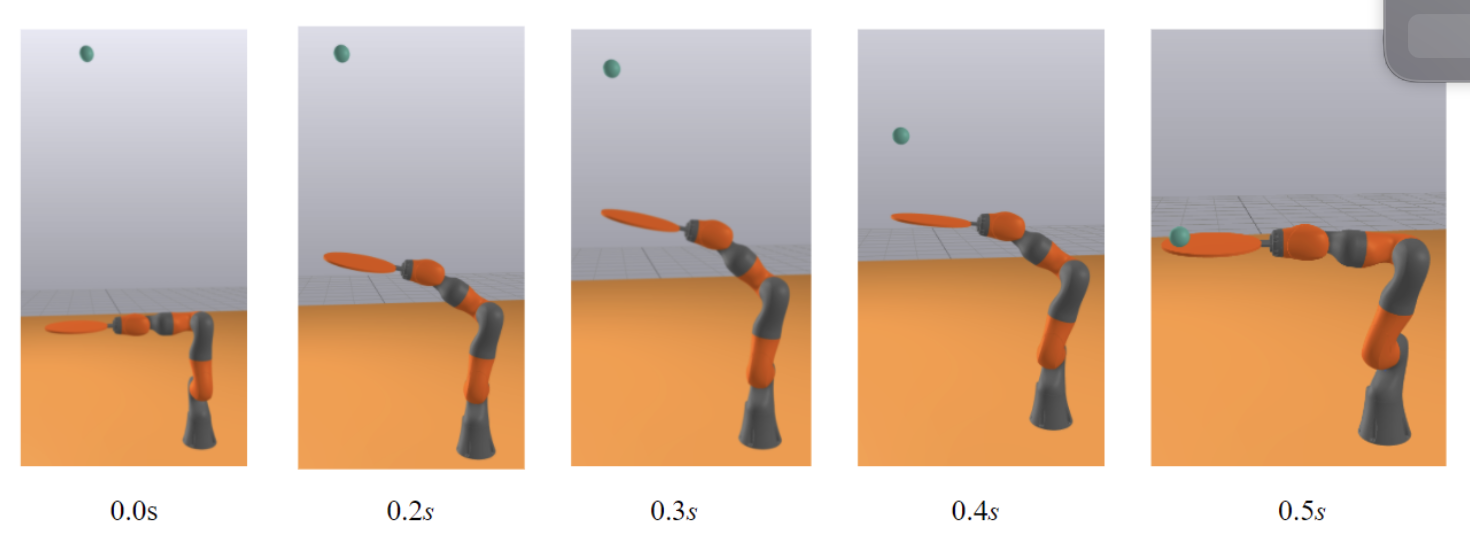
Drake-based finite-state control splits the catch into pre- and post-contact modes, combining projectile modeling with stabilized IK to stop a ping pong ball on an iiwa paddle.
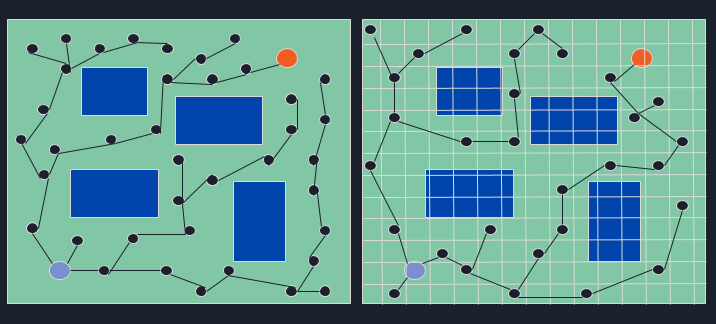
dRRT couples discrete sampling with search-based refinement, reusing computation to accelerate 5-DOF arm planning versus traditional RRT.

Tested quantization-aware autoencoders that couple commit loss and training-time discretization to achieve compact latent codes for images and text.

Collected simulator trajectories, trained a CNN to map images to steering commands, and demonstrated closed-loop driving in the Unreal Blocks environment.
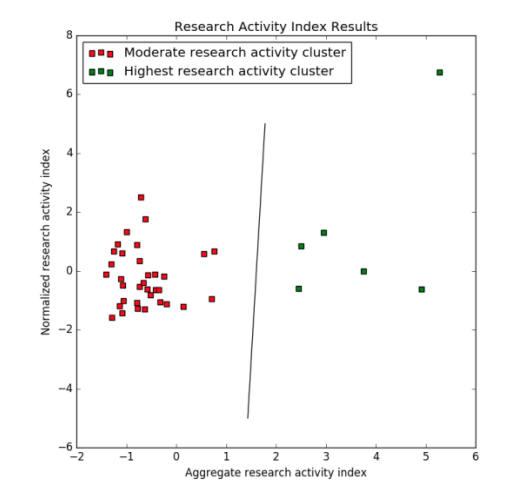
Designed quantitative criteria for research HEIs in India, applied them to top institutions, and surfaced 40 universities and 32 engineering colleges as research-focused.
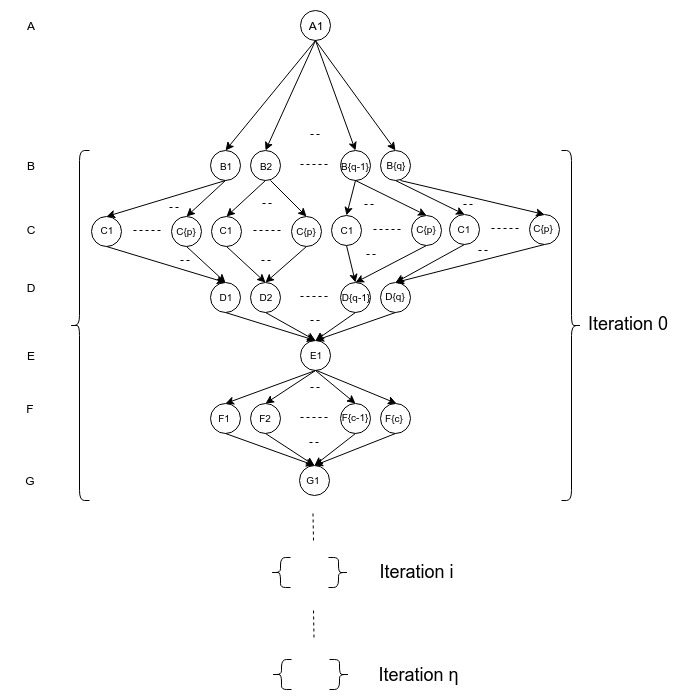
Work-efficient GPU traversal expands frontier vertices in parallel and accelerates DFS-based analytics on massive DAGs.
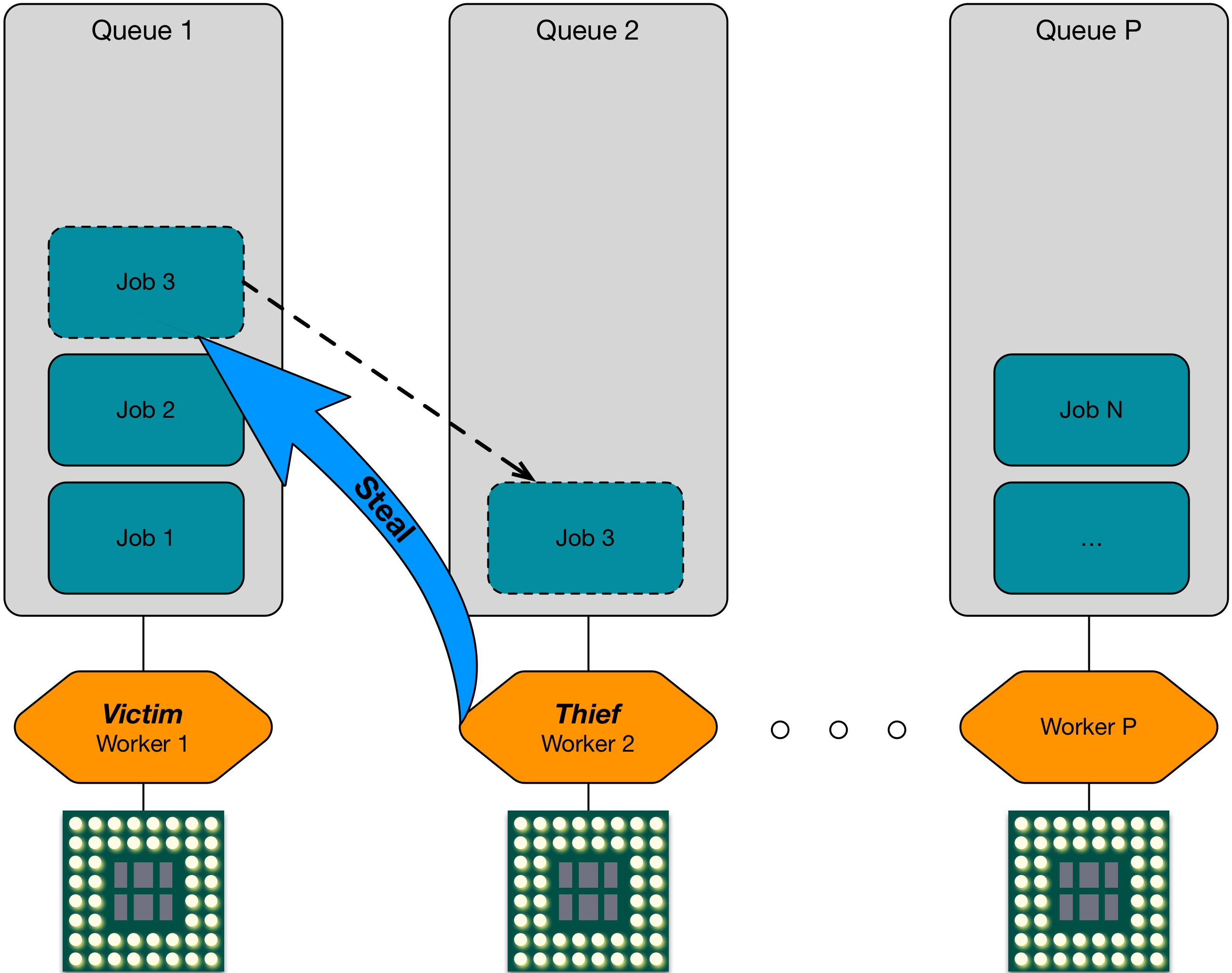
COTTON couples work stealing with CPU frequency scaling policies tuned by task heuristics, cutting energy use while preserving throughput.
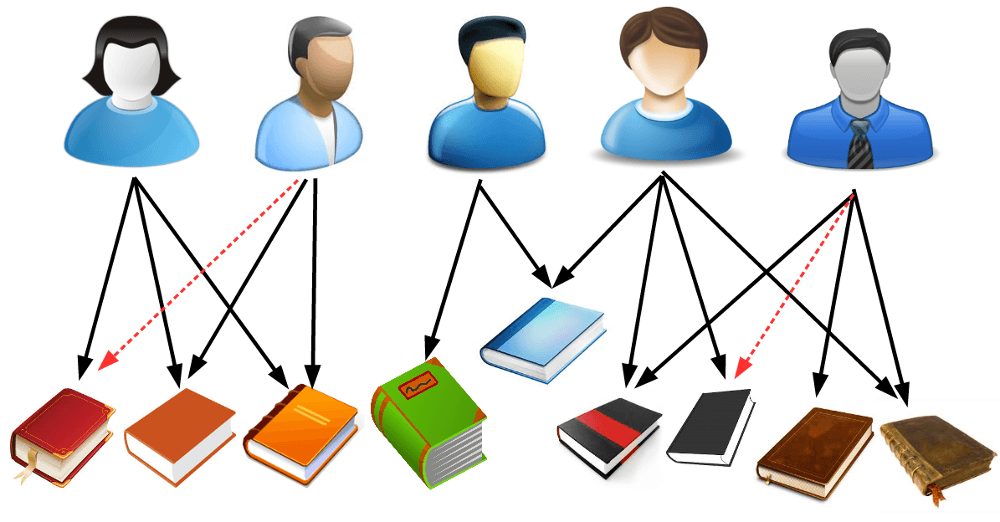
Collected contribution signals, formed confidence-weighted implicit ratings, and trained a custom autoencoder that surfaces relevant GitHub repos for contributors.
Published in RISS Working Papers Journal, 2018
Benchmarked the accuracy limits of DSRC GPS for pedestrian safety applications and fused smartphone and DSRC signals to cut low-speed localization error.

Published in IEEE Transactions on Intelligent Transportation Systems, 2020
Derived a hierarchical Bayesian model that learns accurate bus dwell-time distributions from sparse data, enabling reliable arrival predictions for signal priority systems.
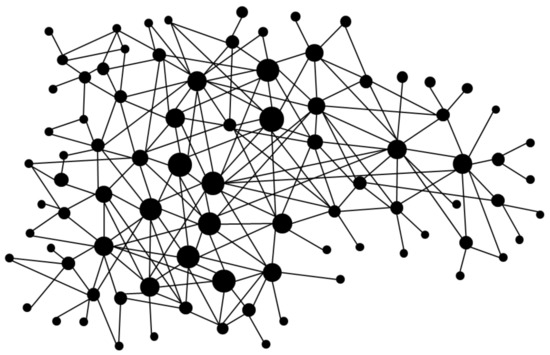
Published in Principles of Social Networking, Springer, 2021
Analyzed how targeted node and edge removals disrupt community structure, introducing heuristics that stay near-optimal even on large-scale social graphs.
Scales Bayesian sequential forecasting to real-time deployments by swapping costly MCMC with Nested Sampling, keeping accuracy high even in small, non-stationary datasets.

Published in ICAPS | Workshop on Hierarchical Planning, 2022
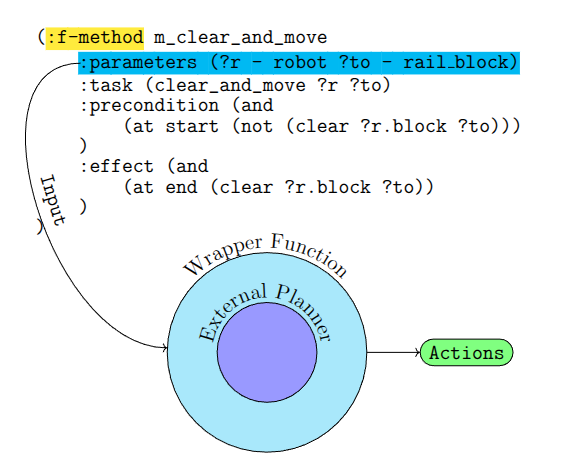
Combined timeline-based scheduling with HTNs to coordinate multi-robot teams under resource constraints, yielding resilient plans compared to state-of-the-art temporal planners.
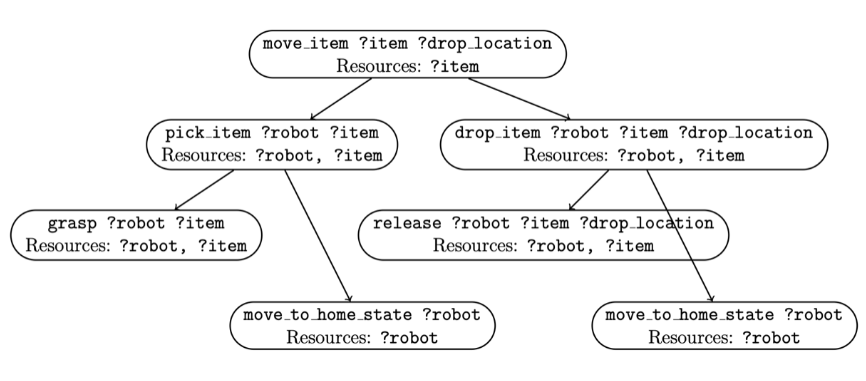
Published in CoRL | Workshop on Learning Effective Abstractions for Planning, 2023
Trained recurrent models that learn search heuristics for multi-agent planners, accelerating long-horizon planning while preserving solution quality.

Published in AAAI Spring Symposium on Human-Like Learning (Oral), 2024
Bridged conditional planning with hierarchical RL to iteratively refine risk budgets, enabling agents to tackle long-horizon tasks while respecting safety constraints.
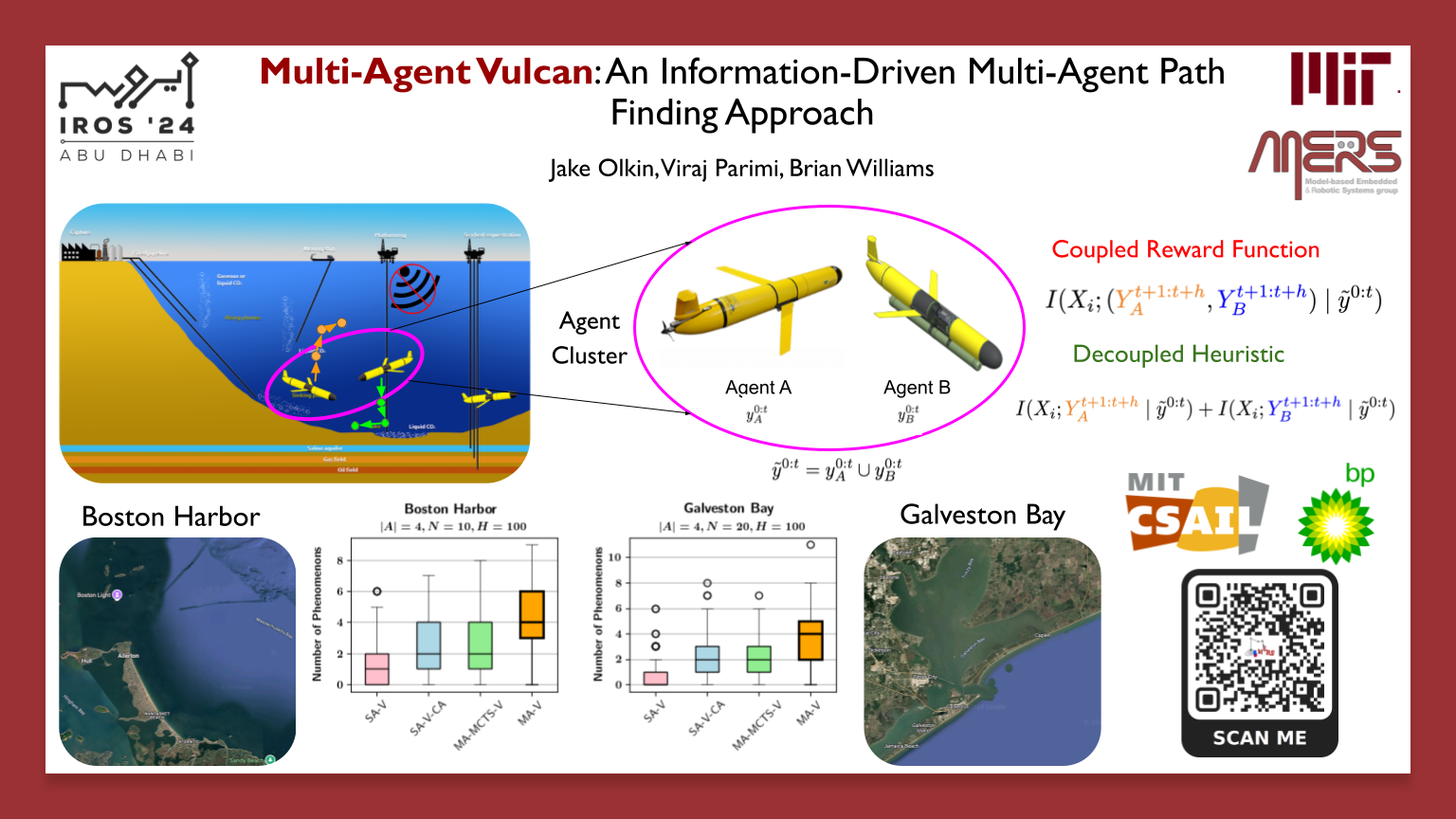
Published in IROS, 2024
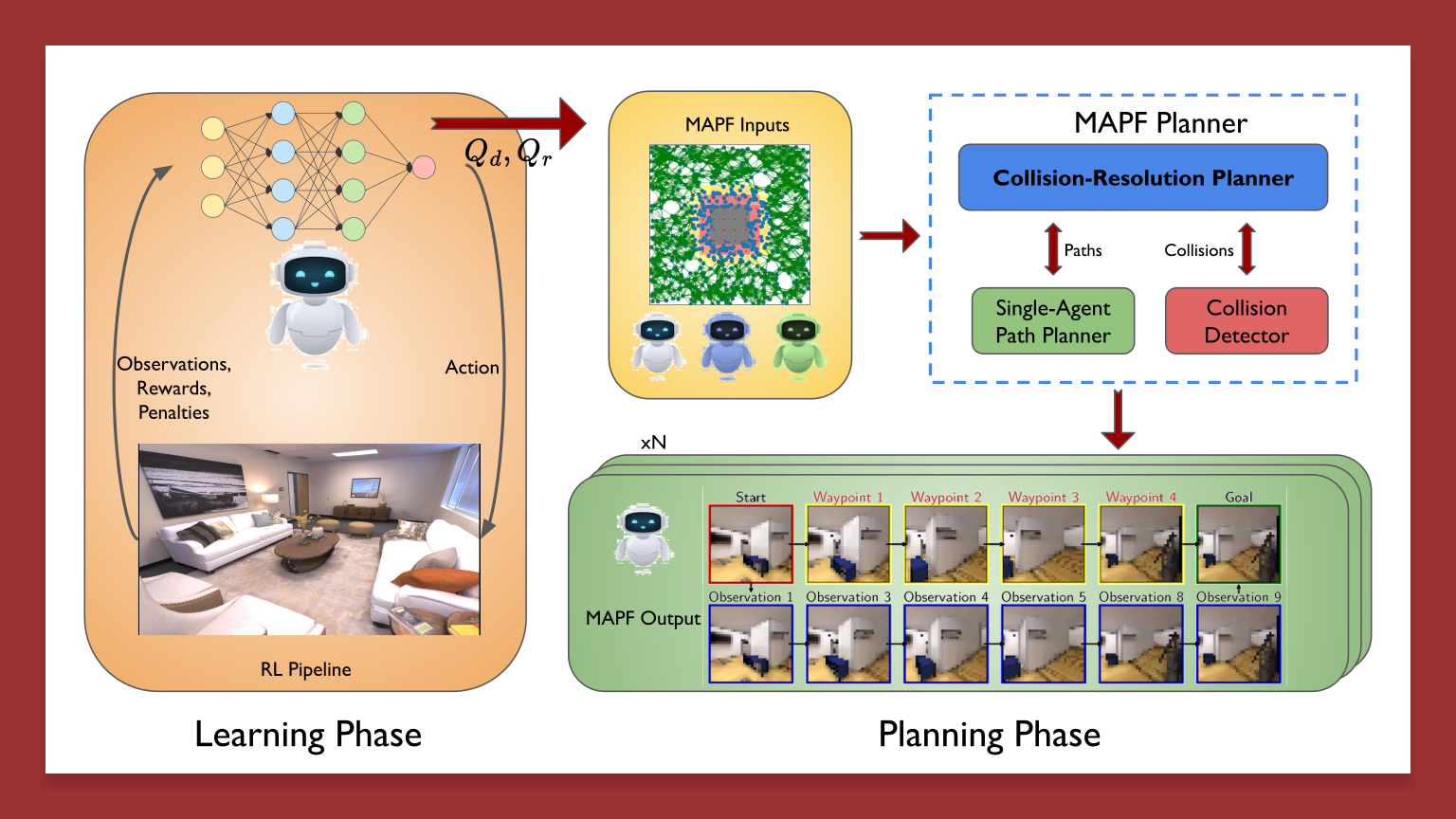
Extended MAPF with an information-driven heuristic and distributed coordination so multi-robot explorers maximize unique observations even under intermittent communication.
Published in NERC | Extended Abstract, 2024
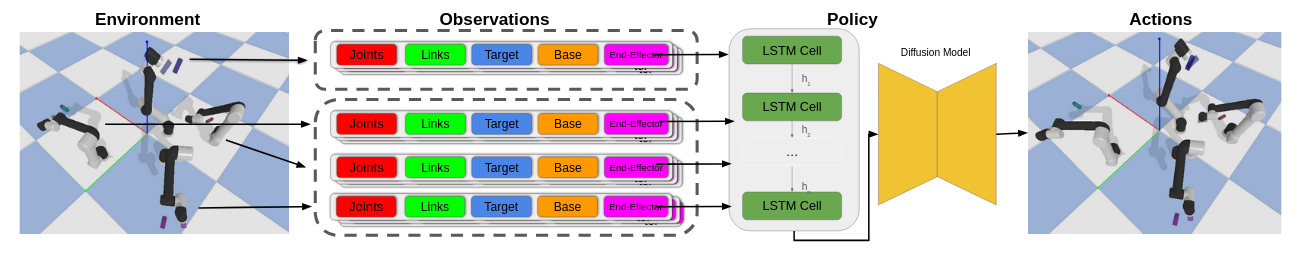
Leveraged diffusion models to seed decentralized multi-arm planning with high-quality samples, reducing coordination failures in tightly coupled manipulation tasks.
Published in ICRA, 2025
Also presented at NeurIPS Workshop on Intrinsically Motivated Open-Ended Learning ; CoRL Workshop on Learning Effective Abstractions for Planning
Unified conflict-based search with goal-conditioned safe RL to plan long-horizon multi-agent navigation that stays safe without sacrificing efficiency.
Published in CoRL, 2025
Also presented at RSS Workshop on Scalable and Resilient Multi-Robot Systems
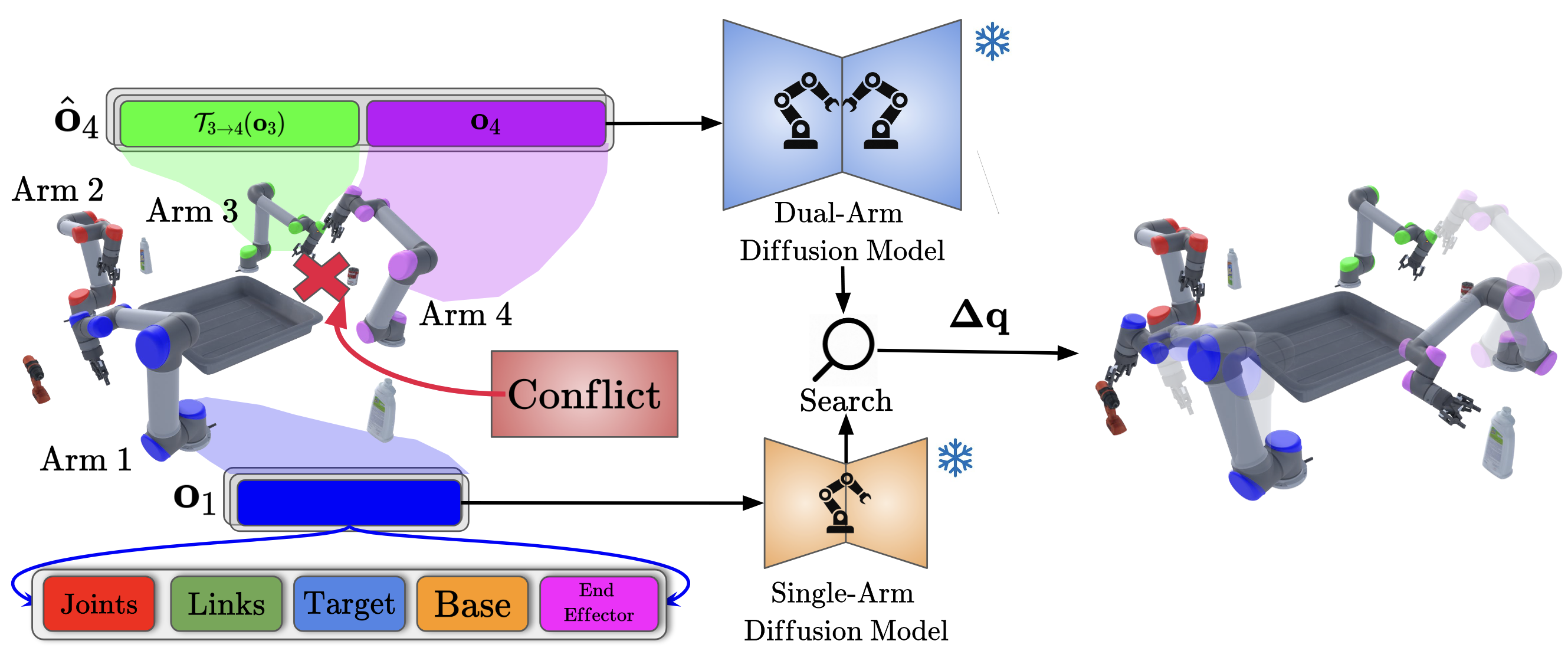
Diffusion-guided MAPF decomposition lets us scale multi-arm planning by pairing single-arm generators with a collision-resolving duet, beating data-hungry baselines across large teams.

Published in ICAPS, 2026
Also presented at ICAPS Workshop on Bridging the Gap Between AI Planning and Reinforcement Learning (Oral) ; CoRL Workshop on Safe and Robust Learning for Operation in the Real World
Dynamic CBS risk budgeting lets visual multi-agent teams push through higher-risk corridors when it pays off, delivering faster, collision-free plans while still honoring the user’s $\Delta$ constraint.
Published in Masters Thesis | Carnegie Mellon University, 2021
Extends hierarchical task networks with temporal reasoning to create schedules for multi-robot teams that stay robust to resource conflicts and deadline uncertainty in deep-space habitats.