
Automatic Reward Densification
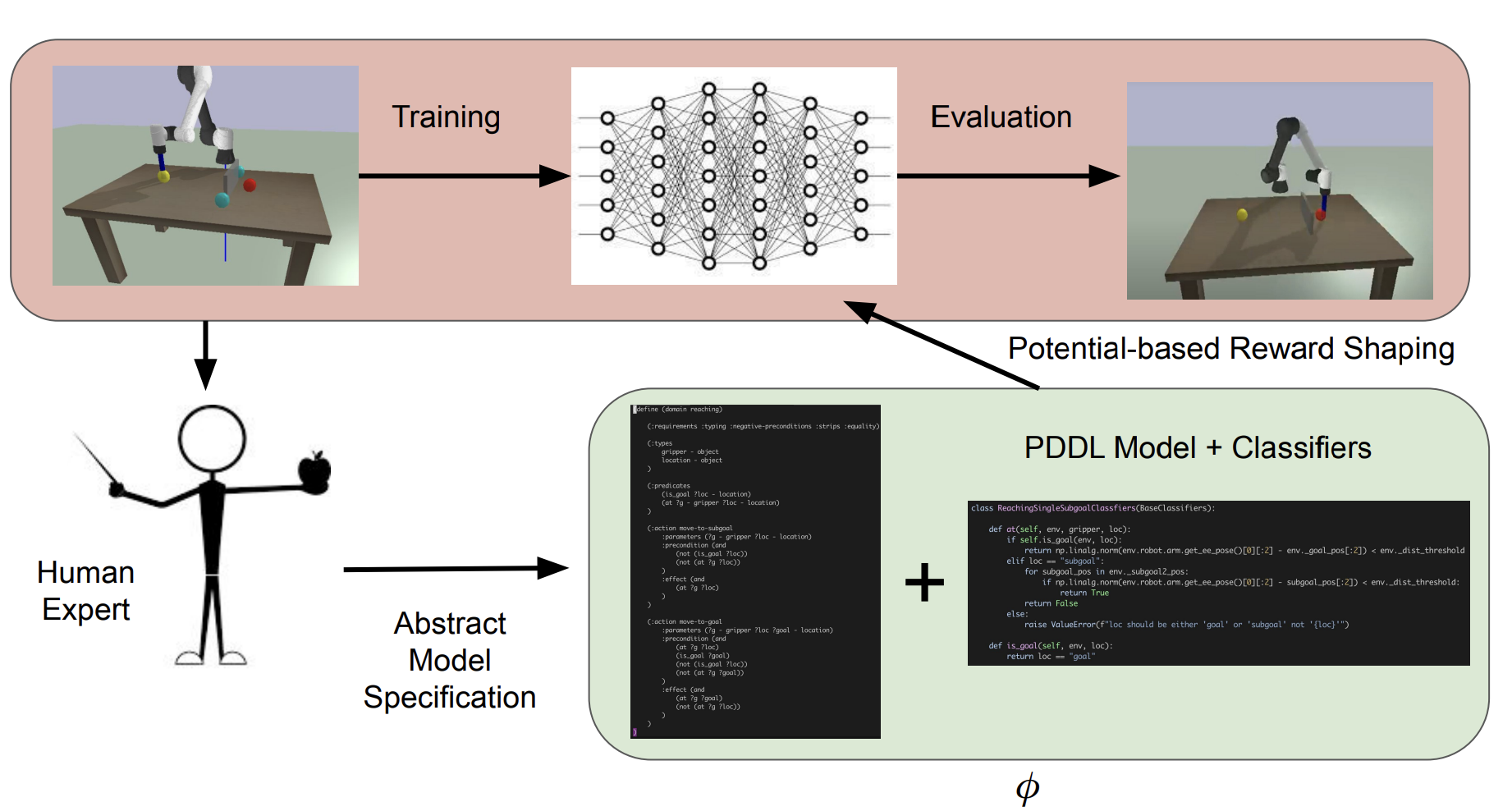
We implemented a system that leverages classical planning over human-specified PDDL models to automatically increase the density of sparse, goal-based rewards for robotic tasks. We first revisited plan-based potential shaping for discrete domains, proved its soundness, reproduced prior methods, and evaluated them on continuous control problems with varying PDDL granularities. Building on these insights, we proposed a dynamic distance-varying potential that consistently accelerates learning across three robotic benchmarks. Our analysis highlights how model granularity and potential weighting interact, and shows that with careful tuning our shaped reward matches or exceeds handcrafted dense signals.